
Understanding Standby Clusters in Patroni: Cross-Datacenter Disaster Recovery for PostgreSQL
If you run PostgreSQL in production at any scale, you’ve probably already adopted Patroni to manage high availability within a […]
If you run PostgreSQL in production at any scale, you’ve probably already adopted Patroni to manage high availability within a […]

One question has become increasingly common among startup founders:“How do we add AI to our product?” It’s a valid question,
Why Every Startup Should Think AI-First (Even Before Writing the First Line of Code) Read Post »

If you run PostgreSQL at scale with Patroni, you’ve probably hit the point where every replica streaming directly from the

In the previous Journey June AI Edition article, we explored a question that many founders quietly ask themselves: Will AI
How Learning to Delegate to Machines Changed the Way I Think About Leadership Read Post »

Introduction PostgreSQL is well known for its rock-solid replication features. For many workloads, physical replication works just fine. But as
Part 1: pglogical – Flexible Logical Replication for PostgreSQL Read Post »
As part of our Journey June – AI Edition series, we recently spoke with Hari Kiran, Founder of OpenSource DB,
The Fear No One Admits: Will AI Replace Founders? Read Post »

High-Level Upgrade Flow The complete upgrade follows eight sequential phases: Phase 1: Pre-checks on both servers—version confirmation, replication health, and

Production database incidents rarely look like what you expect. They don’t arrive with sirens. They accumulate quietly — a mount
When a Disk Expansion Brought Down a PostgreSQL Archive Pipeline Read Post »
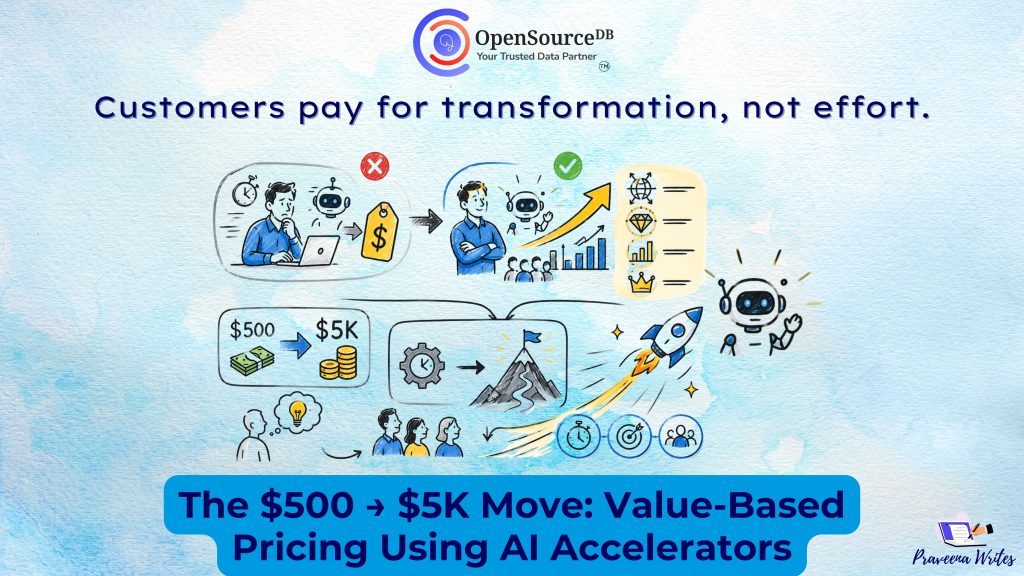
The $500 → $5K Move: Value-Based Pricing in the AI Era For years, service businesses priced work based on effort:More
The $500 → $5K Move: Value-Based Pricing using AI accelerators Read Post »

Welcome to our latest blog!! In the real world, not every PostgreSQL deployment gives you the freedom to choose your
Setting Up Logical Replication on PostgreSQL (Windows) Read Post »
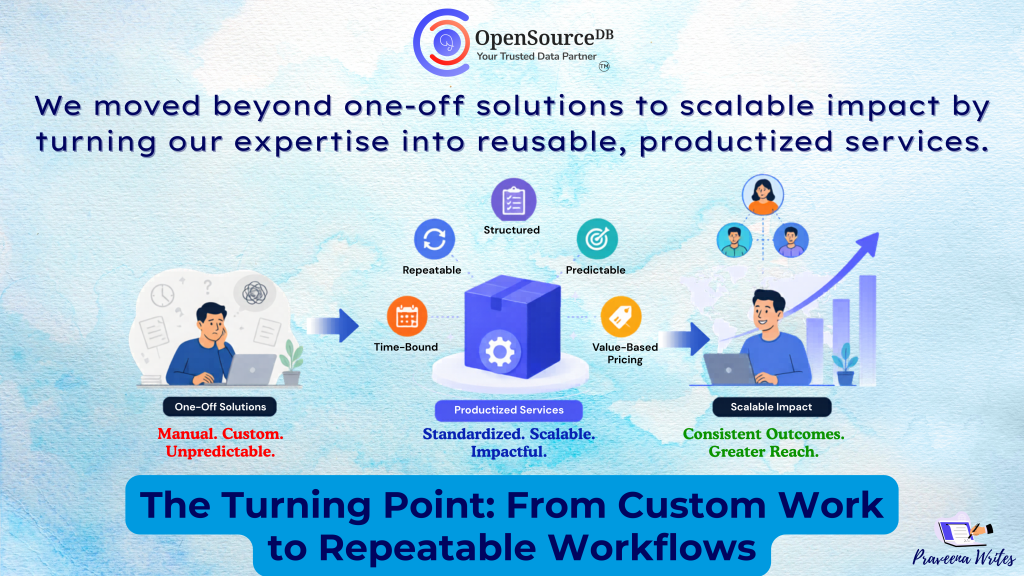
For years, service businesses operated on a familiar model: time, effort, and people. More hours often meant more revenue. More
We Productized Our Services with AI: Pricing Lessons We Learned Read Post »

In today’s data-driven systems, high availability (HA) is no longer optional—it’s a fundamental requirement. Applications are expected to remain responsive
End-to-End Guide to MariaDB MaxScale Installation for HA Architecture Read Post »
Last week, we explored a simple but important question: Would you hire an AI Project Manager? Not as a replacement
I Gave Every Team Member an AI Agent… What Happened Next? Read Post »
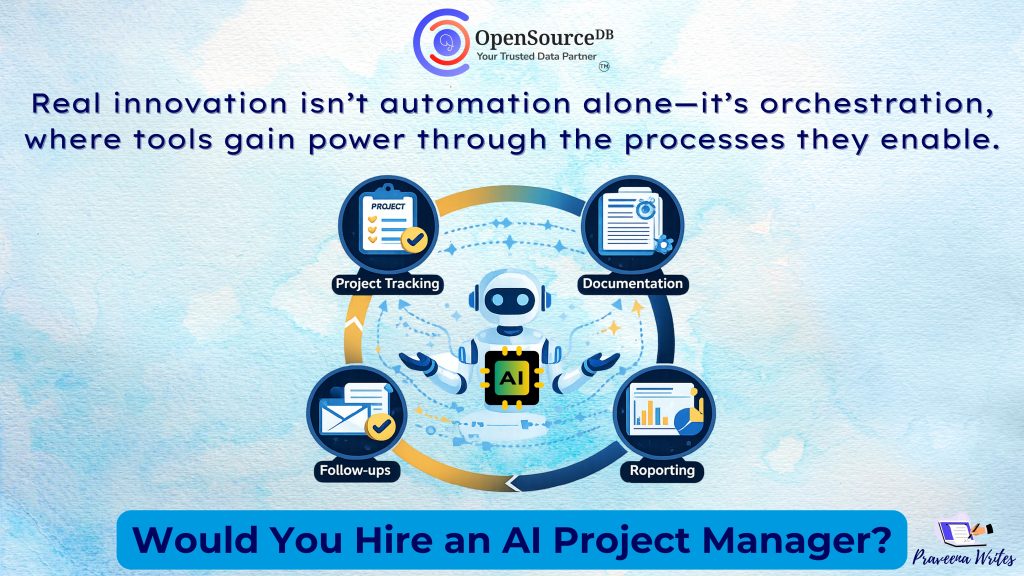
“Any update?” “Did we capture this?” “Can someone document this?” These questions were not exceptions in our workflow. They were
Would You Hire an AI Project Manager? Read Post »

plpgsql_check extension Plpgsql_check is a powerful postgres extension that acts as a linter and validator for pl/pgsql functions, catching bugs
Syntax Is Not Enough: Catching Hidden Semantic Errors in PostgreSQL with plpgsql_check Read Post »

Introduction In modern production environments, demand for more than basic database reliability. They require high availability, scalability, and the ability
Setting Up MariaDB Replication Across 3 Nodes with MaxScale Read Post »

In last week’s post, “Fine-Tuning vs RAG vs API-First,” we explored how most teams can unlock AI value without building
Why SMBs Don’t Need to Train Models (Yet) Read Post »

On March 12th & 13th, 2026, I had the privilege of staffing the Aiven booth at PGConf India in Bengaluru,
Customers Speak: Aiven at PGConf India Read Post »

Some partnerships look good on paper. This one looks good in production. OpenSource DB has partnered with HexaCluster — one
Built to Deliver: OpenSource DB & HexaCluster at PGConf India 2026 Read Post »

OpenSource DB and Percona, the global leader in open-source database software, support, and services, and together we’ll be at PGConf
All In on Open Source: OpenSource DB & Percona at PGConf India 2026 Read Post »

In the world of database administration, performance tuning has long been considered as more room to improve. For decades, DBAs