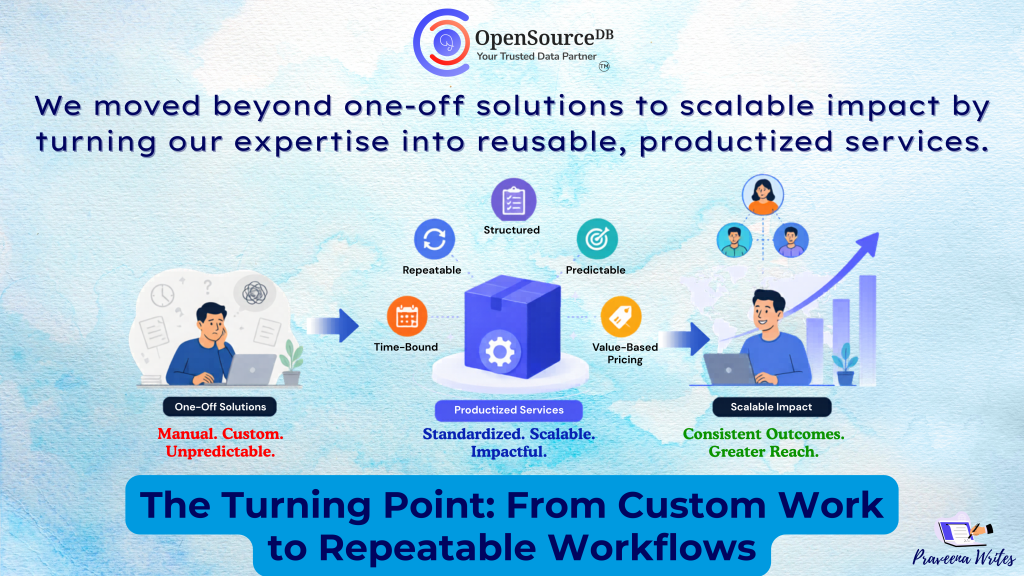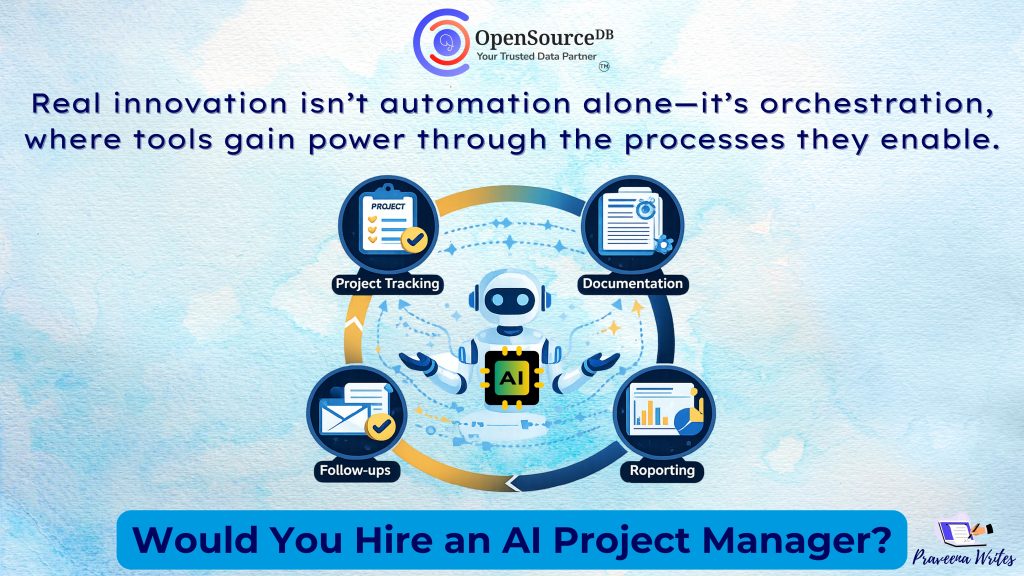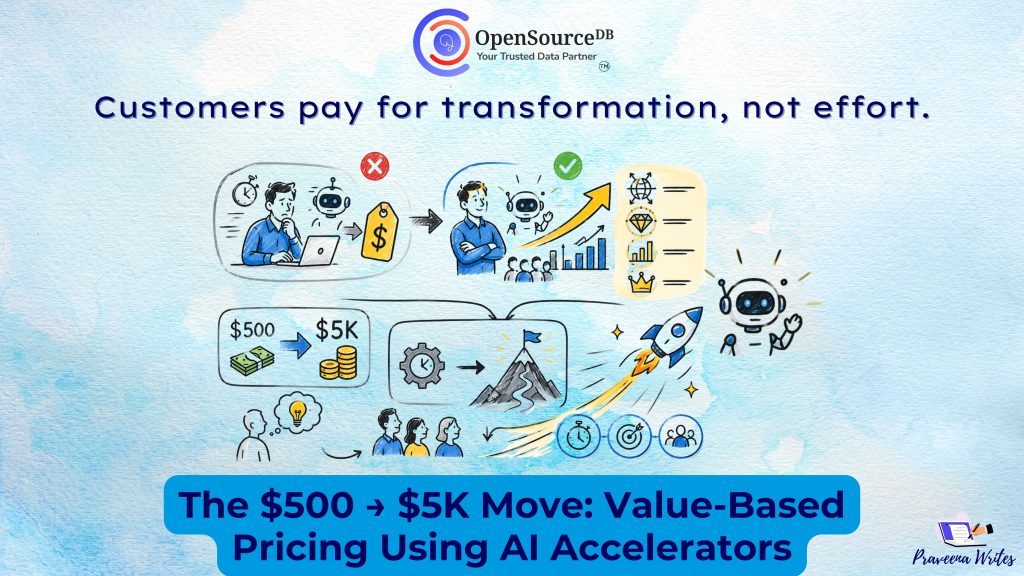
The $500 → $5K Move: Value-Based Pricing using AI accelerators
The $500 → $5K Move: Value-Based Pricing in the AI Era For years, service businesses priced work based on effort:More […]
The $500 → $5K Move: Value-Based Pricing using AI accelerators Read Post »