This year, PostgreSQL’s major upgrade, pg15 was released on 13th October 2022. Here, we examine some more of the new features that were incorporated into release pg15.
If you have not reviewed Part – 1 of this series, you can find it here: PostgreSQL 15 New Features List (Part – 1): General, Configuration & Administration.
This is the second, and final part of this series.
In this post (i.e., Part – 2 of pg15 new features), we’ll look at the new or updated features in Postgres 15 in these areas: Replication, Backup & Recovery. Let us get started.
PostgreSQL 15 New Features List (Part – 2): Replication, Backup & Recovery
- Logical replication publish all tables in schema
- Logical replication row filtering
- Logical replication column lists
- lz4 and Zstandard (zstd) compression for WAL full page writes
- Pg_walinspect
- pg_basebackup server-side compression
- pg_basebackup client compression & decompression
PostgreSQL 15 New Features in detail (Part – 2): Replication, Backup & Recovery
- Logical replication publish all tables in schema
When creating a logical replication publication, a user can specify to publish all the tables within a schema , e.g. CREATE PUBLICATION … FOR ALL TABLES IN SCHEMA ….
If users want to publish tables present in one or more schemas, they have to prepare the table list manually by querying the database, and then create a publication by using the manually prepared list.
PostgreSQL 15 introduces the option TABLES IN SCHEMA, which would allow one or more schemas to be specified, whose tables are selected by the publisher for sending data to the subscriber.
Let’s understand it further with the help of an example:
In Publication node, execute these statements:
[postgres@localhost ~]$ psql -d logical
logical=# create schema schema_1;
logical=# \dn
List of schemas
Name | Owner
—————+——————-
public | pg_database_owner
schema_1 | postgres
(2 rows)
logical=# create table schema_1.t1 (id int,name varchar(20));
logical=# create table schema_1.t2 (id int,name varchar(20));
logical=# GRANT ALL PRIVILEGES ON DATABASE logical TO repuser;
logical=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA schema_1 TO repuser;
logical=# CREATE PUBLICATION schema_all_pub FOR TABLES IN SCHEMA schema_1;
logical=# select * from pg_publication_tables ;
pubname | schemaname | tablename | attnames | rowfilter
———————–+——————–+————–+———————+————–
t1_pub | public | t1 | {id,contact} |
schema_all_pub | schema_1 | t1 | {id,name} |
schema_all_pub | schema_1 | t2 | {id,name} |
(3 rows)
logical=# INSERT INTO schema_1.t1
SELECT generate_series(151,200), ‘randomtext’;
In subscriber node, execute these statements:
logical=# create schema schema_1;
logical=# create table schema_1.t1 (id int,name varchar(20));
logical=# create table schema_1.t2 (id int,name varchar(20));
logical=# CREATE SUBSCRIPTION schema_all_sub CONNECTION ‘host=192.168.113.135 port=5432 user=repuser dbname=logical’ PUBLICATION schema_all_pub;
logical=# select count(*) from schema_1.t1;
count
——-
51
(1 row) - Logical replication row filtering
New features introduced in PostgreSQL 15 allow selective publication of table contents within logical replication publications, through the ability to specify row filter conditions.
Row filters can reduce the amount of data sent by the publisher and processed by the subscriber, thus reducing network consumption and CPU overhead.
Before PostgreSQL 15, if a table was published, all of its rows and columns were replicated. But with PostgreSQL 15, we can now specify row filters and column lists for publications to replicate only the rows and columns that match the specified criteria.
When using filters, the data is filtered before transmission, which brings some overhead. On the other hand, less data is sent, which saves bandwidth and time spent on data transfer. Also, subscribers spend less time replaying transactions.
The following example illustrates the usage of row filtering in logical replication:
In publisher node:
[postgres@localhost ~]$ psql –d logical
logical=# create table emp (id int, name varchar(30),salary int);
After inserting some data into the emp table, the table now looks like this: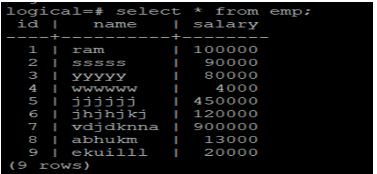
We now create a publication in the publisher node for the emp table with a row filter on the ‘salary’ column.
logical=# create publication row_filter_pub for table emp where (salary >= 100000);
logical=# GRANT ALL PRIVILEGES ON DATABASE logical TO repuser;
logical=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO repuser;
In subscriber node:
[postgres@localhost ~]$ psql -p 5433 -d logical
logical=# create table emp (id int, name varchar(30),salary int);
logical=# CREATE SUBSCRIPTION row_filter_sub CONNECTION ‘host=192.168.113.135 port=5432 user=repuser dbname=logical’ PUBLICATION row_filter_pub ;
Output#:
NOTICE: created replication slot “row_filter_sub” on publisher
CREATE SUBSCRIPTION
logical=# select * from emp;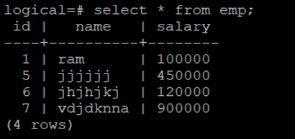
As we can see from the screenshot above, the only rows that got replicated to the subscriber were those that satisfied the row-filter condition (i.e., salary >= 100000).
Let us now see what happens when we update the salary of an employee on the publisher node:Old row New row Transformation no match no match don’t replicate no match match INSERT match no match DELETE match match UPDATE
Testing in publisher:
If we are trying to update a row, we can find the below error:
Additional Notes:
A row filter expression (i.e., the WHERE clause) must contain only columns that are covered by the REPLICA IDENTITY, in order for UPDATE and DELETE operations to be published. For publication of INSERT operations, any column may be used in the WHERE expression. The row filter allows simple expressions that don’t have user-defined functions, user-defined operators, user-defined types, user-defined collations, non-immutable built-in functions, or references to system columns.
The row filter on a table becomes redundant if FOR TABLES IN SCHEMA is specified and the table belongs to the referred schema.
logical=# alter table emp add primary key (id, salary);
logical=# update emp set salary = 10000 where id=1;
On the subscriber node, we would observe the data to be modified as follows:
Before Replication:
logical=# select * from emp;
id | name | salary
—-+———-+——–
1 | ram | 100000
5 | jjjjjj | 450000
6 | jhjhjkj | 120000
7 | vdjdknna | 900000
(4 rows)
After Replication:
logical=# select * from emp;
id | name | salary
—-+————+——–
5 | jjjjjj | 450000
6 | jhjhjkj | 120000
7 | vdjdknna | 900000
(3 rows)
Row Filter Rules
Row filters are applied before publishing the changes. If the row filter evaluates to false or NULL then the row is not replicated. The WHERE clause expression is evaluated with the same role used for the replication connection (i.e. the role specified in the CONNECTION clause of the CREATE SUBSCRIPTION). Row filters have no effect for TRUNCATE command. - Logical replication column lists
Publications for logical replication can now specify which columns to publish. Previously, a publication would publish all columns in a table.
PostgreSQL 15 introduces a new feature that allows specifying column lists in publications, to restrict the amount of data replicated.
Let’s see what the advantages of this feature are, and how to use it.
One might choose to define logical replication column lists for several reasons, such as reducing network traffic, replicating only relevant data, and as a form of security – by omitting replication of sensitive data.
Typically, when using logical replication PUB/SUB, all data changes from the published tables will be replicated to the appropriate subscribers. With the new column lists feature, the user can now limit the replication so that only data from specified columns will be replicated.
Below is an example of configuring the replication with a column list:
In publisher node:
logical=# create table t1 (id int, name varchar(20),contact int ,address text);
logical=# GRANT ALL PRIVILEGES ON DATABASE logical TO repuser;
logical=# GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO repuser;
After inserting some records into the table t1, it now looks like this:
logical=# select * from t1;
Output#:
id | name | contact | address
—-+———–+—————–+———
1 | sudheer | 1234567890 | hyd
2 | srini | 2345678 | bang
3 | ram | 2345678 | gnt
4 | ssssss | 2335655 | hyd
(4 rows)
Create a publication that publishes all changes for table t1, but replicates only columns id and contact:
logical=# CREATE PUBLICATION t1_pub FOR TABLE t1 (id, contact);
In subscriber node:
logical=# create table t1 (id int,name varchar(20),contact int,address text);
logical=# CREATE SUBSCRIPTION t1_sub CONNECTION ‘host=192.168.113.135 port=5432 user=repuser dbname=logical’ PUBLICATION t1_pub;
Output#:
NOTICE: created replication slot “t1_sub” on publisher
CREATE SUBSCRIPTION
logical=# select * from t1 ;
We can notice here that only the selected columns (i.e., id, contact) have been replicated to the subscriber.
Thus Column Lists and Row Filtering features add more flexibility to logical replication. - lz4 and Zstandard (zstd) compression for WAL full page writes
Wal_compression (enum)
This parameter enables compression of WAL using the specified compression method. When enabled, the PostgreSQL server compresses full page images written to WAL when full_page_writes is ‘on’, or during a base backup. A compressed page image will be decompressed during WAL replay. The supported methods are pglz, lz4 (if PostgreSQL was compiled with –with-lz4) and zstd (if PostgreSQL was compiled with –with-zstd). The default value is ‘off’. Only superusers and users with the appropriate SET privilege can change this setting.
Enabling compression can reduce the WAL volume without increasing the risk of unrecoverable data corruption, but at the cost of some extra CPU spent on the compression during WAL logging and on the decompression during WAL replay. - pg_walinspect
The pg_walinspect module provides SQL functions that allow us to inspect the contents of write-ahead log of a running PostgreSQL database cluster at a low level, which can be useful for debugging, analytical, reporting or educational purposes. It is similar to pg_waldump, but accessible through SQL rather than a separate utility.
All the functions of this module will provide the WAL information using the current server’s timeline ID.
All the functions of this module will try to find the first valid WAL record that is at or after the given in_lsn or start_lsn and will emit an error if no such record is available. Similarly, the end_lsn must be available, and if it falls in the middle of a record, the entire record must be available.
How do we use this module?- Create the extension by running the following command:
postgres=# create extension pg_walinspect - Get the current LSN:
postgres=# select pg_current_wal_lsn();
Output#:
pg_current_wal_lsn
————————-
0/1564D60
(1 row) - Do some activity or run some queries using pgbench:
postgres@ubuntu-vm:~$ pgbench -i test
Output#:
dropping old tables…
NOTICE: table “pgbench_accounts” does not exist, skipping
NOTICE: table “pgbench_branches” does not exist, skipping
NOTICE: table “pgbench_history” does not exist, skipping
NOTICE: table “pgbench_tellers” does not exist, skipping
creating tables…
generating data (client-side)…
100000 of 100000 tuples (100%) done (elapsed 0.20 s, remaining 0.00 s)
vacuuming…
creating primary keys…
done in 0.63 s (drop tables 0.00 s, create tables 0.02 s, client-side generate 0.35 s, vacuum 0.12 s, primary keys 0.13 s). - Get the current WAL LSN:
postgres=# select pg_current_wal_lsn();
Output#:
pg_current_wal_lsn
————————
0/25DFD38
(1 row) - Run the function ‘pg_get_wal_records_info’ to read the WAL files content from the starting LSN upto the ending LSN:
postgres=# select start_lsn, end_lsn, prev_lsn, xid, resource_manager, record_type, record_length,
main_data_length, fpi_length, description from pg_get_wal_records_info(‘0/1564D60’, ‘0/25DFD38’);
- Create the extension by running the following command:
- pg_basebackup server-side compression
pg_basebackup now supports server-side compression when creating a backup using the –compress flag. This includes gzip, lz4, and zstd (Zstandard) compression.
Compressing on the server will reduce transfer bandwidth but will increase server CPU consumption.
The following table summarizes our observations when we evaluated the different compression methods on Pg_basebackup on a 1.5 GB database in pg15:Format Compression Time Compressed File Size Compression Ratio gzip 36.82 Sec 101 MB 93.38% zstd 7.56 Sec 85 MB 94.43% Lz4 7.04 Sec 186 MB 87.81%
When the plain format is used, client-side compression may not be specified, but it is still possible to request server-side compression. If this is done, the server will compress the backup for transmission, and the client will decompress and extract it.
Examples:
1. Compression method server side gzip format:
[postgres@localhost backups]$ time pg_basebackup -D /var/lib/pgsql/15/backups/bkpcompress.gzip –compress server-gzip -Ft -h localhost -U test -p 5432 -Xs -P
Output#:
1563009/1563009 kB (100%), 1/1 tablespace
real 0m36.824s
user 0m0.035s
sys 0m5.014s
2. Compression method server side Lz4 format:
[postgres@localhost backups]$ time pg_basebackup -D /var/lib/pgsql/15/backups/bkpcompress.lz4 –compress server-lz4 -Ft -h localhost -U test -p 5432 -Xs -P
Output#:
1563010/1563010 kB (100%), 1/1 tablespace
real 0m7.034s
user 0m0.022s
sys 0m2.655s
3. Compression method server side Zstd format:
[postgres@localhost backups]$ time pg_basebackup -D /var/lib/pgsql/15/backups/bkpcompress.zstd –compress server-zstd -Ft -h localhost -U test -p 5432 -Xs -P
Output#:
1563010/1563010 kB (100%), 1/1 tablespace
real 0m7.564s
user 0m0.023s
sys 0m0.973s - pg_basebackup client compression & decompression
pg_basebackup can now decompress backups using lz4 and zstd (Zstandard) compression.
The option –compress=[{client|server}-]method[:detail] requests compression of the backup. If client or server is included, it specifies where the compression is to be performed. Compressing on the server will reduce transfer bandwidth but will increase server CPU consumption. The default is client except when –target is used.
When the plain format is used, client-side compression may not be specified, but it is still possible to request server-side compression. If this is done, the server will compress the backup for transmission, and the client will decompress and extract it.
Example:
[postgres@localhost backups]$ pg_basebackup -Fp –compress=server-gzip -D /tmp/data -h 172.19.28.1 -U postgres