Blog-4: Apache Drill Magic across PostgreSQL, Local Parquet, and S3
INTRODUCTION:
Welcome back! Following our exploration of data movement between PostgreSQL and Amazon S3 in the previous blog, we now venture into the realm of querying with Apache Drill. In this sequel, we’ll demonstrate the simplicity of querying PostgreSQL tables, local Parquet files, and Parquet files on S3. Join us as we seamlessly connect diverse data sources using the power of Apache Drill and SQL. Let’s continue our data journey.
Configuring the Apache Drill for PostgreSQL
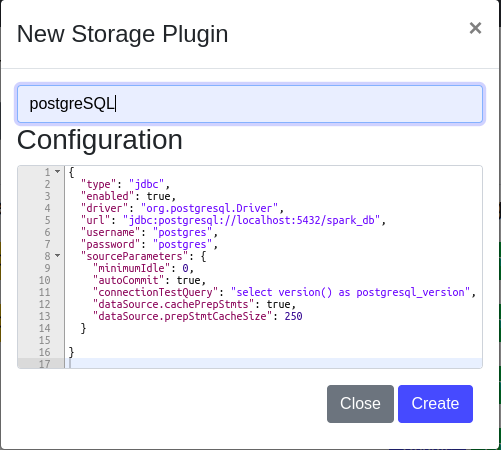
To begin querying PostgreSQL data, the first step is to add the PostgreSQL storage plugin.
- Open Apache drill web UI using http://localhost:8047/storage. Here we need to add this code as a PostgreSQL plugin providing the necessary details such as database URL, username, and password. Save the configuration, now Apache Drill can recognize PostgreSQL as a data source.
- An alternate approach is Apache Drill, which also supports adding storage plugins through CLI(command line interface. we can add the plugin to
storage-plugins-override.conffile.
{
"type": "jdbc",
"enabled": true,
"driver": "org.postgresql.Driver",
"url": "jdbc:postgresql://localhost:5432/spark_db",
"username": "postgres",
"password": "postgres",
"sourceParameters": {
"minimumIdle": 0,
"autoCommit": true,
"connectionTestQuery": "select version() as postgresql_version",
"dataSource.cachePrepStmts": true,
"dataSource.prepStmtCacheSize": 250
}
}
- Now we are ready to explore SQL power across PostgreSQL, We can visualize the PostgreSQL across Drill using commands such as
SHOW SCHEMAS;SHOW DATABASES;
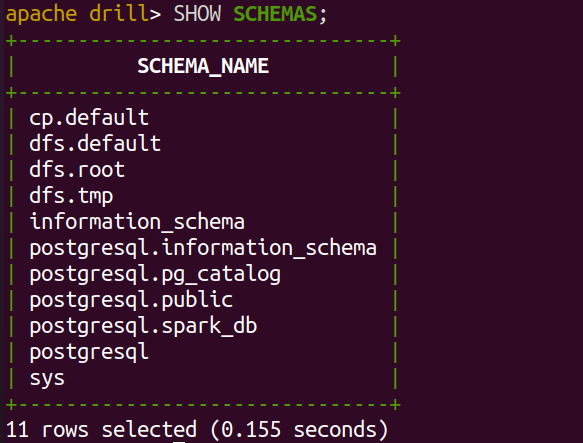
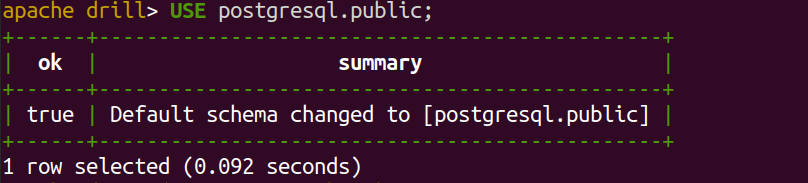
- We can use the specific schema as per our need (example ‘public’) using the command
‘USE postgresql.public’, then we can see the tables present in that database using the ‘SHOW TABLES’ command
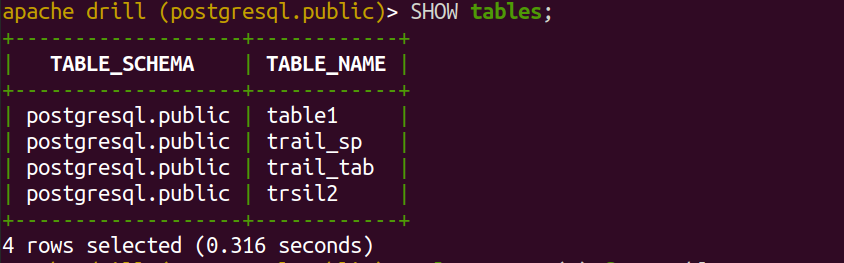
- We can now run the SQL query to read the data in the desired table

Working on Local Parquet Files:
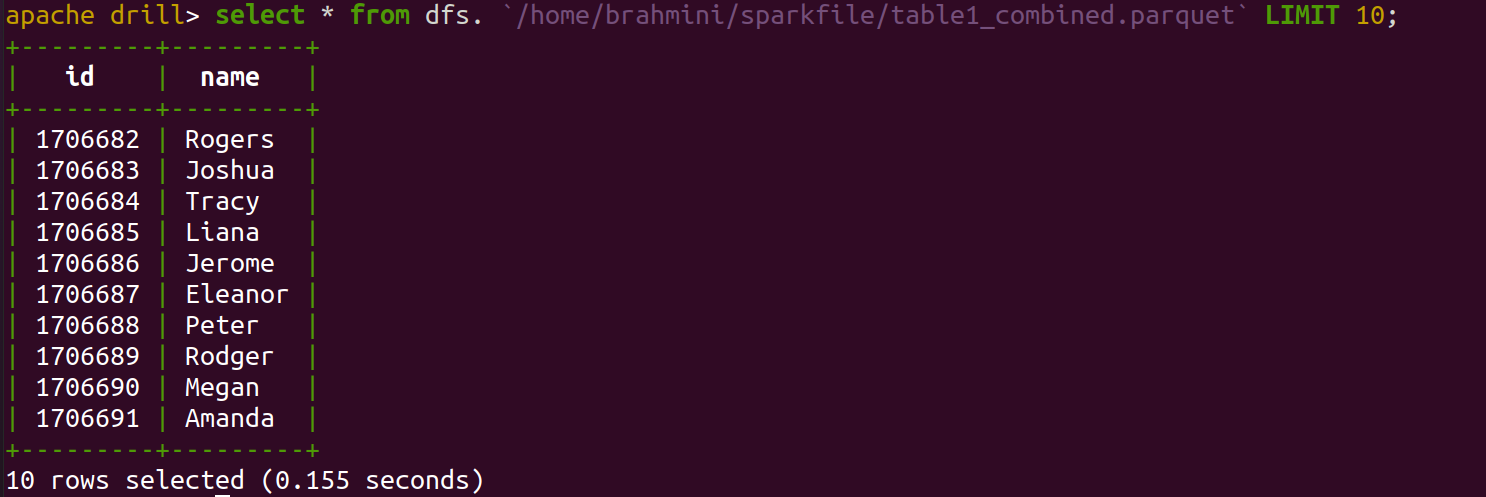
- Now, let’s move on to querying Parquet files stored locally
- For querying parquet files we don’t need any specific plugins to be added as it has parquet file support inbuilt
- The beauty of Drill is that it allows direct querying for extracting data from parquet format and displaying the query output in a readable format
Working on S3 parquet Files:
- As we previously mentioned the Parquet files reading doesn’t need any specific configuration; and Drill seamlessly interacts with S3 as well, but a few things have to be updated in the existing configuration file like the AWS Access Key ID, the Secret Key, and the bucket name for Drill to be able to access data stored in Amazon S3.
- Here is the query for extracting data from Parquet files in the S3 bucket
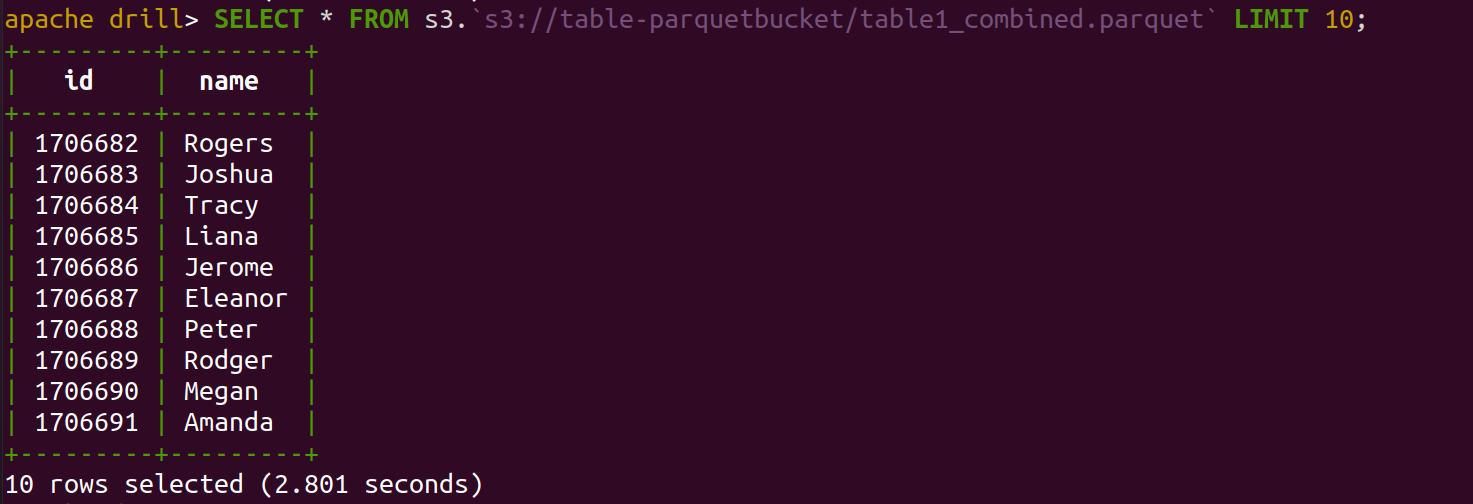
Notice the simplicity – no complex configurations are needed. We can effortlessly translate the data to formats with SQL queries using Apache Drill.
Upcoming??
In this blog, we delved into the magic of Apache Drill, starting our journey from configuring PostgreSQL storage plugins to minimal configuration updates for S3 interactions, we highlighted the simplicity of querying the PostgreSQL, local Parquet files, and S3-residing Parquet files.
Stay tuned for the final installment in our series! The upcoming blog focuses on optimizing performance using Apache Spark and Apache Drill. Get ready to elevate your data engineering game with insights into enhancing query speed and maximizing efficiency. Until then, happy querying and exploring.