We all know that Repmgr (Replication Manager) is an open-source tool designed to manage PostgreSQL replication and facilitate automatic failover. Let’s understand the underlying architecture which is crucial for making informed decisions about your high availability setup. In high availability systems, components span multiple layers, with different configurations assembled based on specific requirements. This post explores the architectural design of a three-node repmgr cluster consisting of one primary, one standby, and one witness node, while highlighting critical considerations around fencing mechanisms and virtual IP management.
The Three-Node Architecture
This architecture example comes from one of our clients. It includes one primary node, one standby node, and one witness node as per the image. For installation and configuration instructions for repmgr, see the blog post linked here.
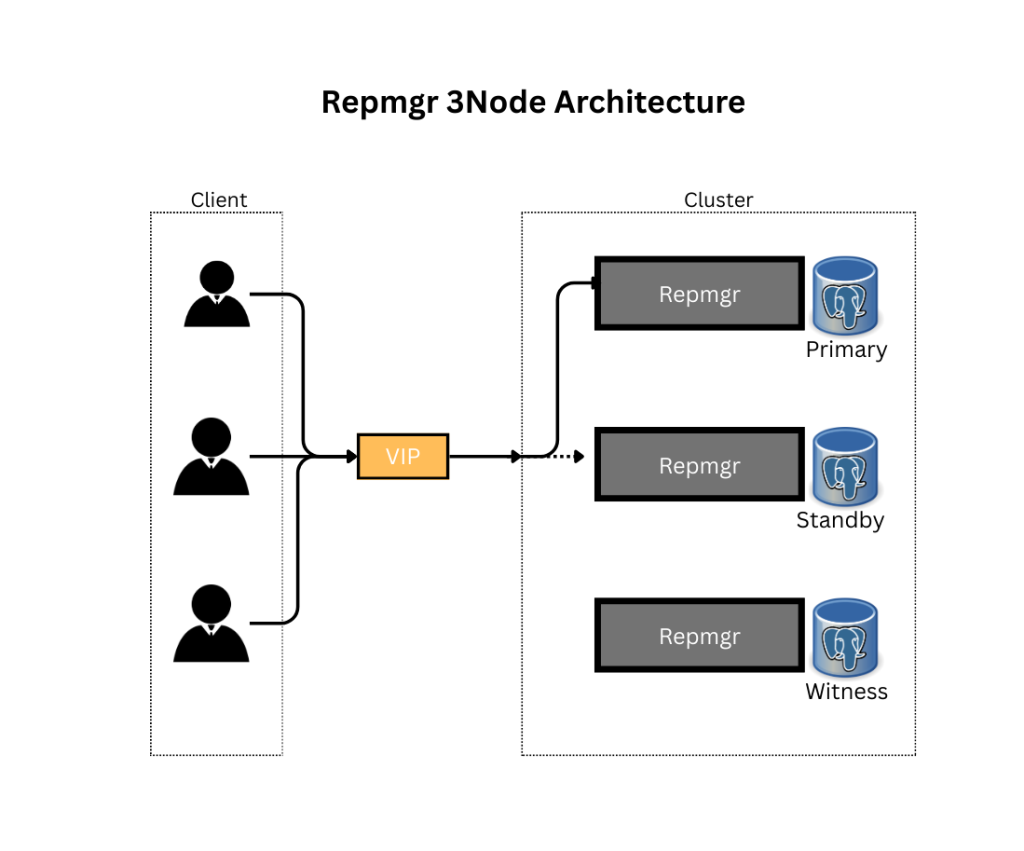
Here, the client/application is connected to the repmgr cluster via Virtual IP without keepalived. Let’s discuss about couple of challenges with this architecture.
The Fencing Problem: repmgr’s Achilles Heel
What is Fencing?
Fencing is the act of isolating a failed or demoted primary node to prevent it from accepting connections or claiming it’s still the primary. This is arguably the most critical aspect of any high availability system, and it’s where repmgr shows its architectural limitations.
Why repmgr Lacks True Fencing
Repmgr does not include built-in fencing mechanisms. This is not an oversight but rather a design decision that places the burden on the administrator. The architecture relies on:
- Application-level routing (via pgBouncer, HAProxy, etc.)
- Custom scripts triggered during failover
- Manual intervention in some scenarios
The fundamental issue is that repmgr operates on a “message-passing” model for fencing. When a failover occurs, repmgrd executes the promote_command, which can be wrapped in custom scripts to
- Update App-level routing configurations
- Modify routing tables
- Adjust load balancer targets
- Disable the old primary
However, this approach has a critical weakness: it assumes messages will be delivered.
The Message Delivery Problem
Consider this disaster scenario:
- Datacenter 1 experiences a power outage (Primary + Witness down)
- Datacenter 2’s standby detects failure, promotes itself
- Failover script attempts to update pgBouncer in DC1 (fails – DC1 is down)
- DC1 power is restored
- Old primary boots up, still believes it’s the primary
- pgBouncer in DC1 never received the update
- Applications in DC1 connect to the old primary
- Split-brain achieved
The architectural flaw is clear: repmgr cannot guarantee that the old primary will be fenced if the fencing mechanism relies on network communication to that node during or after the failure.
Virtual IP Without Keepalived: Why It’s Problematic
The VIP Concept
A Virtual IP (VIP) is an IP address that can float between nodes. Applications connect to the VIP, and the underlying infrastructure ensures the VIP points to the current primary. This provides a stable connection endpoint that doesn’t change during failover.
Why Keepalived is Typically Used
Keepalived implements the VRRP (Virtual Router Redundancy Protocol) to manage VIPs. It provides:
- Automatic health checking
- Gratuitous ARP broadcasts to update network switches
- Priority-based VIP assignment
- Built-in fault detection
Issues with VIP Management in repmgr Without Keepalived
When using a VIP with repmgr but without a dedicated VRRP implementation like Keepalived, several architectural problems emerge.
For example, Manual IP Management Complexity. Without Keepalived, you must manually manage the VIP through scripts.
Conclusion
Repmgr provides a solid foundation for PostgreSQL replication management, particularly when you understand its architectural strengths and limitations. The three-node architecture with primary, standby, and witness effectively solves the quorum problem in two-datacenter scenarios.
However, repmgr’s lack of built-in fencing mechanisms is a significant architectural limitation that requires careful mitigation through external tools and custom scripts. Similarly, managing VIPs without Keepalived introduces numerous failure modes and operational complexities that can undermine the reliability of your high availability setup.
For production deployments, the architecture should include:
- Proper quorum
- Robust fencing
- Reliable VIP management
- Connection routing
- Comprehensive monitoring and alerting
By understanding these architectural considerations, you can design a repmgr-based PostgreSQL cluster that balances simplicity with reliability, or make an informed decision to use alternative solutions that better match your availability requirements.
Remember: high availability is not about preventing failures—it’s about having an architecture that handles failures gracefully and safely.
Additional resources on High availability cluster management tools:
- Step-by-Step Guide to PostgreSQL HA with Patroni: Part I
- Step-by-Step Guide to PostgreSQL HA with Patroni: Part 2
- Step-by-Step Guide to PostgreSQL HA with Patroni: Part 3
- Building PostgreSQL HA Systems with repmgr
- Troubleshooting PostgreSQL Replication Setup Errors with repmgr
- PostgreSQL Automatic failover with repmgr
- Postgres HA Architecture: Eliminating SPoF with Keepalived