Introduction:
In today’s fast-paced digital landscape, real-time data processing is no longer a luxury but a necessity. Businesses need to react to changes instantly, whether for updating inventories, personalising user experiences, or detecting fraud. This need for immediacy has led to the adoption of Change Data Capture (CDC) techniques, which enable the continuous capture and delivery of database changes to downstream systems.
Why this setup?
Setting up a data pipeline from PostgreSQL to Kafka using Debezium CDC and docker offers several compelling advantages:
- Real-time Data Capture: Debezium captures changes to data as they occur, allowing applications to react in near real-time.
- Low impact on source systems: Debezium uses the transaction log to capture data changes, instead of running batch jobs, which can reduce the impact on source systems.
- Fault tolerance: Debezium ensures continuous data availability and reliability. Even if an application stops unexpectedly, it can resume reading from the topic where it left off after restarting.
- Snapshotting: Debezium captures a consistent snapshot of the database to ensure a reliable starting point.
- Automatic topic creation: Debezium automatically generates kafka topics for each table.
- Data serialisation: Debezium supports various data formats, including Avro, JSON Schema, and Protobuf.
- Low delay: Debezium produces change events with a very low delay, in the millisecond range, while avoiding increased CPU usage.
- Scalability: Kafka clusters are easy to build and scale.
Overview of the setup:
In this blog, we’ll stream data from PostgreSQL to kafka topics using debezium Change data capture (CDC) on docker. The setup involves using Docker compose to create and manage containers for PostgreSQL, Kafka, debezium, and Kafka UI, for enabling a seamless and real-time data pipeline.
Components:
- PostgreSQL: An open-source relational database management system (RDBMS) that stores the data. We’ll use the logical replication feature of PostgreSQL to capture changes.
- Kafka: A distributed streaming platform that serves as the intermediary, capturing the data changes and making them available to downstream consumers.
- Debezium: An open-source CDC tool that captures row-level changes in the database and sends them to Kafka topics. It leverages PostgreSQL’s logical decoding feature to stream changes in real-time.
- Kafka UI: A web-based user interface to monitor and interact with Kafka clusters, topics, and messages.
Step by step Guide:
- Docker Compose File: Explains the structure and purpose of each service in the docker-compose.yml file. Create a new folder, and within that, create the docker-compose.yml file with relevant content as described below.
- PostgreSQL Dbserver: Describes the setup of the PostgreSQL container.
- Kafka: Explains the configuration of the Kafka broker.
- Connect: Details the Debezium Connect service setup.
- Kafka-UI: Describes the Kafka UI for monitoring.
Docker compose file:
version: '3.9'
services:
postgres:
image: postgres:16
container_name: dbserver
hostname: dbserver
ports:
- 30432:5434
volumes:
- ./pgdata:/var/lib/postgresql/data
environment:
- POSTGRES_USER=user
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=mydb
kafka:
image: apache/kafka
container_name: kafka
hostname: kafka
ports:
- 9092:9092
environment:
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=true
- KAFKA_ADVERTISED_HOST_NAME=kafka
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
- KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR=1
volumes:
- ./cfg/server.properties:/mnt/shared/config/server.properties
connect:
image: debezium/connect:nightly
container_name: connect
hostname: connect
ports:
- 8083:8083
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- SCHEMA_HISTORY_INTERNAL_KAFKA_BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- KAFKA_AUTO_CREATE_TOPICS_ENABLE=true
- CONFIG_STORAGE_TOPIC=connect_configs
- OFFSET_STORAGE_TOPIC=connect_offsets
- STATUS_STORAGE_TOPIC=connect_statuses
kafka-ui:
image: provectuslabs/kafka-ui
container_name: kafkaui
hostname: kafkaui
depends_on:
- kafka
ports:
- 8888:8080
restart: always
environment:
- KAFKA_CLUSTERS_0_NAME=local
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092Running the containers: Start the docker cluster by running the command: ‘docker compose up -d‘ as illustrated below:
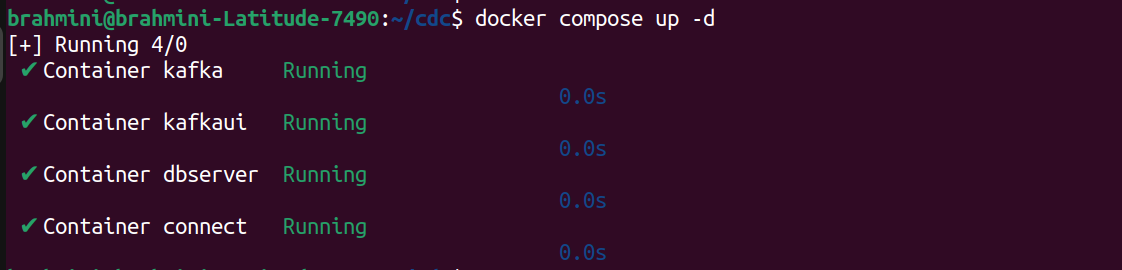

Configuring PostgreSQL for CDC:
Steps to enable Logical replication in PostgreSQL by modifying ‘postgreql.conf‘ file.
wal_level = logical
max_wal_senders = 10Statements to add to ‘pg_hba.conf‘ file
host replication postgres 0.0.0.0/0 trust
host replication user 0.0.0.0/0 trustRestart the PostgreSQL server/services after making the changes to ‘postgresql.conf’ and ‘pg_hba.conf’ files.
Setting up Postgres Connector for Debezium:
Define connector configuration in /kafka/config directory and add the connector file. This is the JSON configuration. Save this content in a file with the name ‘connect-postgres-source.properties’ within the /kafka/config directory.
{
"name": "postgres-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "dbserver",
"database.port": "5434",
"database.user": "user",
"database.password": "postgres",
"database.dbname": "mydb",
"topic.prefix": "pgdata",
"plugin.name": "pgoutput"
}
}Adding the Postgres Connector for Debezium:
- Use curl or Postman to POST this configuration to the Kafka Connect REST API, from within the
/kafka/configdirectory:
curl -d @"connect-postgres-source.properties" -H "Content-Type: application/json" -X POST http://localhost:8083/connectorsMonitoring and verifying Data flow:
Once the Postgres Connector for Debezium is successfully created, Debezium would automatically create a unique topic for each of the tables, and stream the data from the initial snapshot. You could now now verify the data flow from PostgreSQL to Kafka, and monitor it from the Kafka UI at http://localhost:8888
Following the initial snapshot, any change that gets done on the Postgres tables is automatically streamed into the Kafka topics, which can again be verified from the Kafka UI at http://localhost:8888
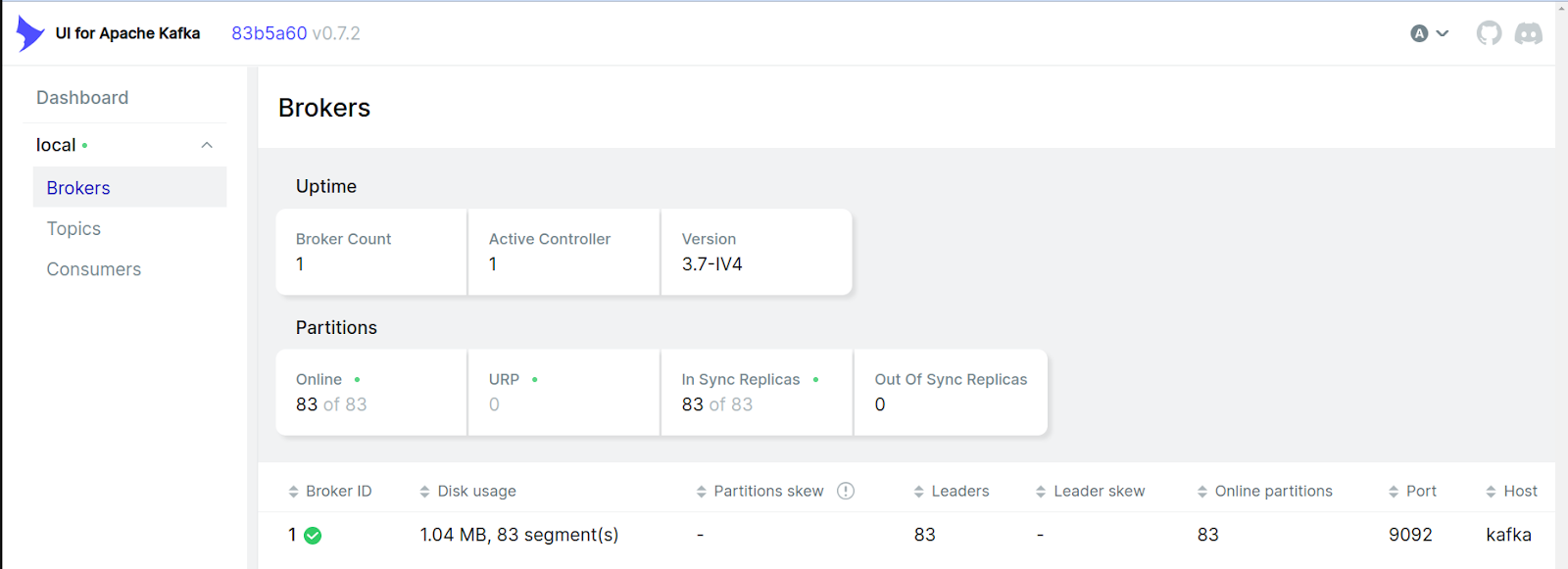
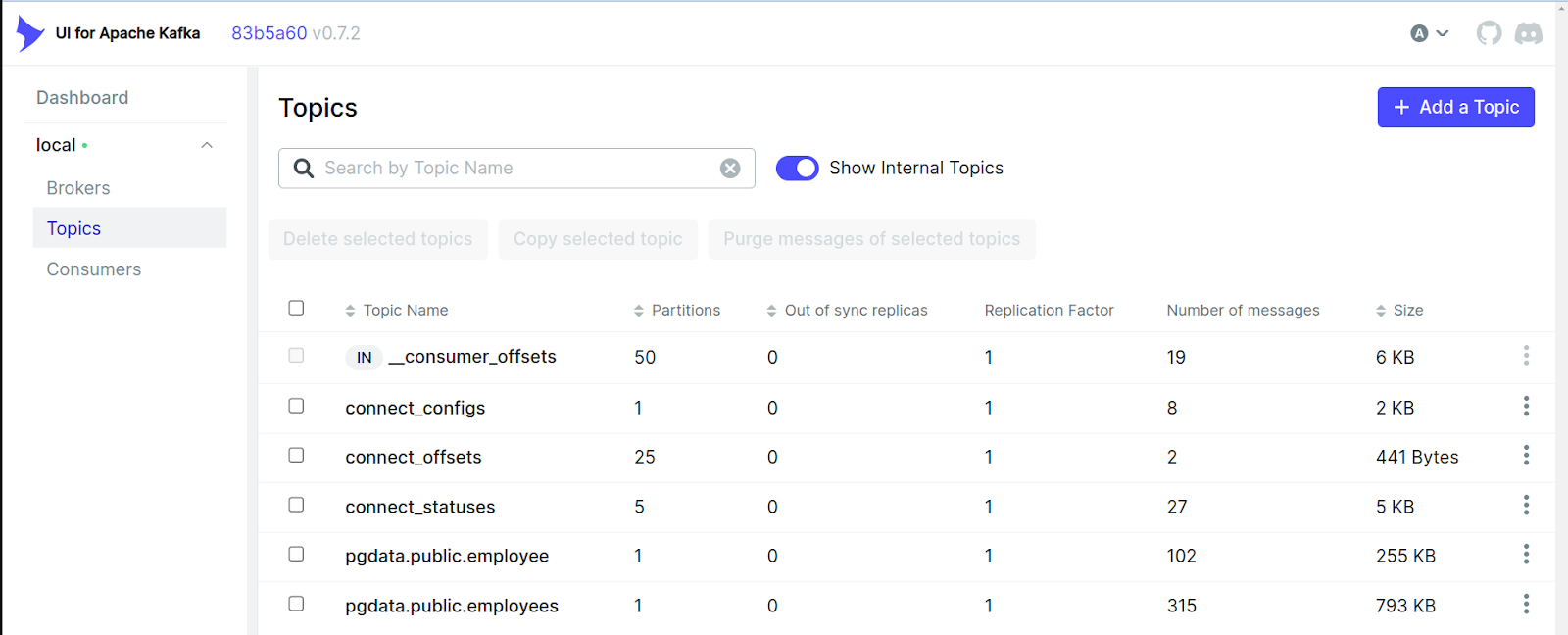
In the above screenshots, we can see the Kafka UI page and topics which contain the PostgreSQL data. We can view the actual data by drilling down on the topics.
Conclusion:
In this blog, we set up a real-time data pipeline from PostgreSQL to Kafka using Debezium CDC and Docker. This approach ensures minimal impact on source systems, fault tolerance, low latency, and scalability. Using Docker Compose, we easily deployed PostgreSQL, Kafka, Debezium, and Kafka UI for efficient data streaming and monitoring. This setup enables businesses to react instantly to data changes, enhancing operational efficiency.
Experience the power of real-time data streaming with PostgreSQL, Kafka, and Debezium. Happy streaming!