
In the earlier posts, we’ve had an Overview of Postgres Extensions, and we’ve also looked at the pg_cron extension in some detail. In today’s post, we shall examine the pg_stat_statements, pgstattuple, and pg_buffercache extensions.
Using pg_stat_statements extension
The pg_stat_statements view is a valuable PostgreSQL extension that offers insights into the execution statistics of SQL statements processed by the PostgreSQL server. This information can be instrumental in identifying and addressing performance issues within your database system.
You can leverage the pg_stat_statements View in several ways to trace and tackle performance problems:
Identifying Slow Queries: To pinpoint queries that consume significant time during execution, sort the view by the total_time column in descending order:
SELECT * FROM pg_stat_statements
ORDER BY total_time DESC;This reveals which queries are likely culprits for performance bottlenecks.
Identifying Frequently Executed Queries: Use the calls column to discover queries that are executed frequently. These queries may not individually be time-consuming, but their high frequency can impact performance:
SELECT * FROM pg_stat_statements
ORDER BY calls DESC;Addressing frequently executed queries is crucial for overall system optimization.
Analyzing Resource Usage: By examining the rows and memory columns, you can determine which queries consume significant resources. Queries with high row values process substantial data, while those with high memory values utilize extensive memory:
SELECT * FROM pg_stat_statements
ORDER BY rows DESC;and
SELECT * FROM pg_stat_statements
ORDER BY memory DESC;Identifying resource-intensive queries aids in resource management.
Detecting Query Plan Changes: The plan_changes column highlights queries that frequently alter their execution plans. Queries exhibiting many plan changes can pose optimization challenges for PostgreSQL:
SELECT * FROM pg_stat_statements
ORDER BY plan_changes DESC;Understanding such queries is essential for query plan stability.
Once problematic queries are identified, you can harness the data from the pg_stat_statements view to scrutinize their execution plans. This analysis offers insights into the reasons behind slow performance and provides guidance on optimizing query execution for improved database efficiency.
Using pgstattuple extension
The pgstattuple module provides various functions to obtain tuple-level statistics.
Because these functions return detailed page-level information, access is restricted by default. By default, only the role pg_stat_scan_tables has EXECUTE privilege. Superusers of course bypass this restriction. After the extension has been installed, users may issue GRANT commands to change the privileges of the functions to allow others to execute them. However, it might be preferable to add those users to the pg_stat_scan_tables role instead.
Create the extension using the CREATE EXTENSION command as follows:
osdb=# CREATE EXTENSION pgstattuple;
CREATE EXTENSIONWe can check the installed pgstattuple extension from the PSQL prompt as follows:

pgstattuple returns a relation’s physical length, percentage of “dead” tuples, and other info. This may help users determine whether a vacuum is necessary or not. The argument is the target relation’s name (optionally schema-qualified) or OID.
For example:
Create a table named ‘t1’ and insert 10,000 rows of random data into the ‘t1’ table using the following SQL commands.
osdb=# CRATE TABLE t1 (id int, name varchar);
CREATE TABLE
osdb=#INSERT INTO t1 SELECT generate_series (1,10000),md5(generate_series(1,10000)::text);
INSERT 0 10000
We can check the table t1 tuple data as following
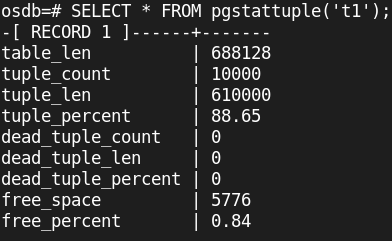
Delete a portion of the data from the ‘t1’ table to intentionally generate some dead tuples.
We can assess table-level bloat by executing the following command:

To reclaim space and remove dead tuples, you can perform an VACUUM operation on the ‘t1’ table. This will free up space previously occupied by the dead tuples.
Now, we can check the dead tuple count, length, and percentage after completion of the vacuum.
This free space can now be used to store new rows inside your table.

Conclusion:
In this example, we have demonstrated the process for checking and addressing bloat in a single table. You can now apply sorting and filtering techniques as needed to identify and address bloat in other tables within your PostgreSQL database.
Using pg_buffercache extension
The pg_buffercache module provides a means for examining what’s happening in the shared buffer cache in real-time.
Create the extension using the CREATE EXTENSION command as follows:
osdb=# create extension pg_buffercache;
CREATE EXTENSIONWe can check the installed extension from the PSQL prompt as follows:
osdb=# \dx pg_buffercache List of installed extensions
Name | Version | Schema | Description
----------------+---------+--------+---------------------------------
pg_buffercache | 1.3 | public | examine the shared buffer cache

After the creation of the pg_buffercache extension, it will create a view called pg_buffercache with the following structure:
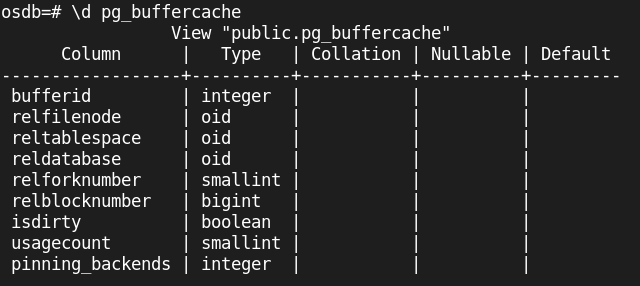
The view created after the installation of the extension called pg_buffercache has several columns.
- bufferid, the block ID in the server buffer cache
- relfilenode, which is the folder name where data is located in relation
- reltablespace, Oid of the tablespace relation uses
- reldatabase, Oid of database where location is located
- relforknumber, fork number within the relation
- relblocknumber, age number within the relation
- isdirty, true if the page is dirty
- usagecount, page LRU (least-recently-used) count
With a configuration using 128MB of shared_buffers and an 8kB block size, PostgreSQL allocates 16,384 buffers in the shared buffer cache. Consequently, the pg_buffercache extension provides information on the same number of 16,384 rows, each representing a buffer in the cache.
The below query provides the number of buffers used by each relation of the current “osdb” database.
osdb=# SELECT c.relname, count(*) AS buffers
FROM pg_buffercache b INNER JOIN pg_class c
ON b.relfilenode = pg_relation_filenode(c.oid) AND
b.reldatabase IN (0, (SELECT oid FROM pg_database
WHERE datname = current_database()))
GROUP BY c.relname
ORDER BY 2 DESC
LIMIT 10;
relname | buffers
--------------------------------+---------
t1 | 88
pg_proc | 46
pg_attribute | 34
pg_statistic | 23
pg_type | 19
pg_class | 17
pg_depend | 15
pg_depend_reference_index | 15
pg_operator | 14
pg_proc_proname_args_nsp_index | 14
(10 rows)

As part of this series, below are a couple of other blog posts we’ve posted before:
Postgres Beyond the Basics: Exploring Extensibility
Introducing pg_cron – The Automation task master
Conclusion:
pg_stat_statements, pgstattuple, and pg_buffercache are powerful extensions for PostgreSQL that aid in fine-tuning your database system, optimizing query performance, and ensuring efficient memory usage. They would serve as a valuable addition to your toolkit for database management and optimization.