In Part 1, we built a complete open-source CDC pipeline using Debezium, Apache Kafka, and Oracle LogMiner to stream real-time changes from Oracle Database to PostgreSQL. Now comes the most critical phase of any migration: Testing & Validation.
A CDC pipeline is reliable only if the validation process behind it is flawless. Before executing the final production cutover, we must ensure:
- Connectors are running without errors.
- Kafka topics are receiving change events.
- DML operations (
INSERT,UPDATE,DELETE) replicate correctly. - No replication lag or data inconsistency exists.
- Monitoring and troubleshooting tools are verified.
This section walks through structured validation steps to confirm that your Oracle → PostgreSQL synchronization is working flawlessly.
Testing & Validation
Before testing CDC flow, confirm that the debezium_user in PostgreSQL:
- Exists
- Has correct privileges on the
cdc_targetdatabase - Has DML access on on the target schema, which is the the
hrschema in our case
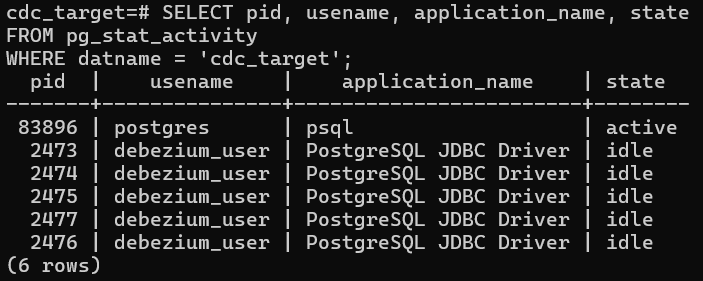
Check the replication user is active in the postgres:
Validate Oracle to Debezium connection (Source Connector)
We first verify whether the Oracle Source Connector is running correctly.
Note: You need to have the json module installed in Python for the following command to work.
ubuntu@ip-172-31-38-9:~/debezium-cdc$ curl -s http://localhost:8083/connectors/oracle-hr-connector/status | python3 -m json.tool
{
"name": "oracle-hr-connector",
"connector": {
"state": "RUNNING",
"worker_id": "172.18.0.5:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.18.0.5:8083"
}
],
"type": "source"
}What This Confirms
- Connector is successfully connected to Oracle
- LogMiner is actively reading redo/archive logs
- Kafka Connect worker is operational
- No task failures exist
Validate Debezium To PostgreSQL Sink Connector Status
After confirming the Oracle source connector is running, validate that the PostgreSQL sink connector is also active.
ubuntu@ip-172-31-38-9:~/debezium-cdc$ curl -s http://localhost:8083/connectors/postgres-hr-sink/status | python3 -m json.tool
{
"name": "postgres-hr-sink",
"connector": {
"state": "RUNNING",
"worker_id": "172.18.0.5:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.18.0.5:8083"
}
],
"type": "sink"
}What This Confirms
- The JDBC Sink connector is successfully connected to PostgreSQL.
- Kafka consumer group is active.
- Events are being consumed from Kafka topics.
- No task failures exist.
- The pipeline is fully operational end-to-end.
If the state is anything other than RUNNING, inspect logs and resolve issues accordingly:
docker logs kafka-connectValidate Debezium to Kafka topic creation
Next, verify that change events are being written to Kafka topics using the following command:
ubuntu@ip-172-31-38-9:~$ docker exec -it kafka bash -c \
"kafka-topics --list --bootstrap-server localhost:29092 | grep oracle"
oracle
oracle.HR.COUNTRIES
oracle.HR.DEPARTMENTS
oracle.HR.EMPLOYEES
oracle.HR.JOBS
oracle.HR.JOB_HISTORY
oracle.HR.LOCATIONS
oracle.HR.REGIONSWhat this confirms
- Debezium successfully created topics
- Schema capture is working
- HR tables are being monitored
- CDC events are flowing into Kafka
Each table in Oracle corresponds to a Kafka topic:
oracle.HR.Test DML replication – UPDATE operation
Now we validate real-time replication.
SQL> UPDATE hr.employees SET salary = 99999 WHERE employee_id = 100;
1 row updated.
SQL> COMMIT;
Commit complete.Then validate the in target database:
psql -U postgres
Password for user postgres:
psql (18.1 (Ubuntu 18.1-1.pgdg24.04+2), server 17.7 (Ubuntu 17.7-3.pgdg24.04+1))
Type "help" for help.
postgres=# \c cdc_target
#Let's do a select query
cdc_target=# SELECT employee_id, first_name, salary FROM hr.employees WHERE employee_id = 100;
employee_id | first_name | salary
-------------+------------+--------
100 | Steven | 99999
(1 row)What this confirms
- Change was captured from Oracle redo logs
- Debezium published the event to Kafka
- JDBC Sink connector consumed the event
- PostgreSQL applied the UPSERT correctly
This validates end-to-end CDC flow.
Monitor connector status
Monitoring & Management
Testing isn’t complete without monitoring the pipeline health.
# List all connectors
#Note: You need to have the jq utility installed on your Kafka server.
ubuntu@ip-172-31-38-9:~$ curl -s http://localhost:8083/connectors | jq
[
"postgres-hr-sink",
"oracle-hr-connector"
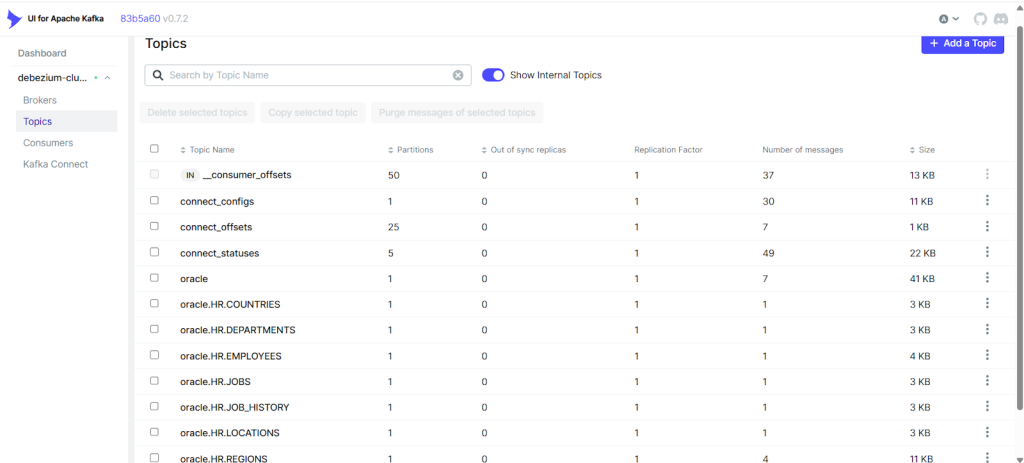
]Validate Topics in Kafka UI
You can also visually inspect:
- Topics created
- Message count
- Partition offsets
- Consumer lag
Using Kafka UI, confirm:
oracle.HR.EMPLOYEEShas messages- Sink connector consumer group is active
- Offsets are moving forward
This gives a visual confirmation of pipeline health.
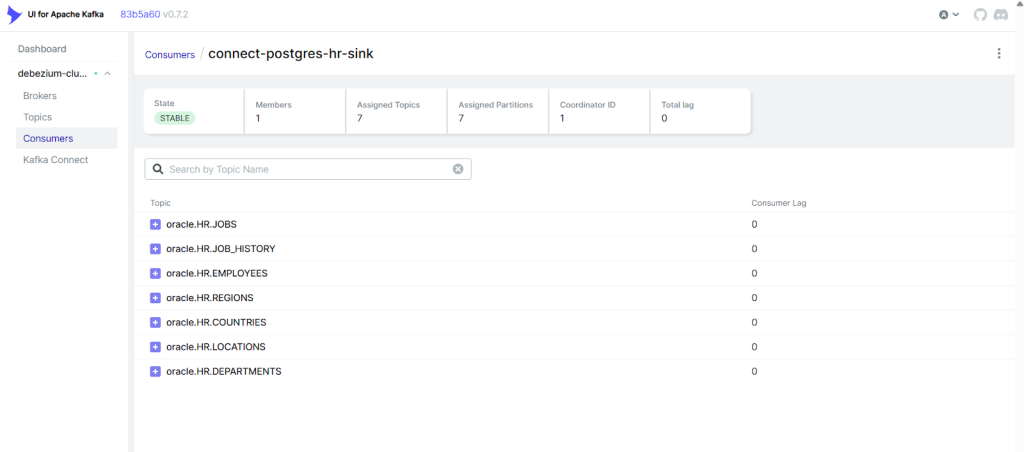
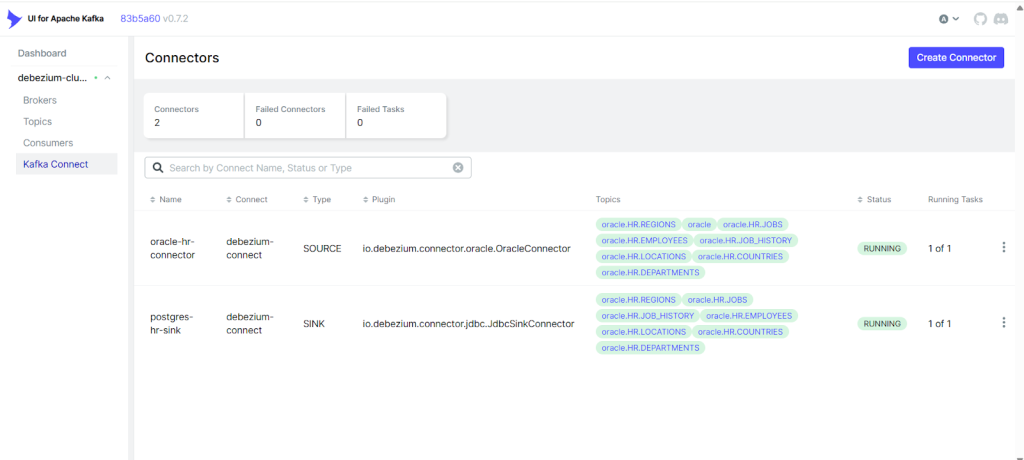
To validate the list of connections are active in Kafka.
View Kafka messages directly
To inspect raw CDC events:
docker exec -it kafka bash -c \
"kafka-console-consumer \
--bootstrap-server localhost:29092 \
--topic oracle.HR.EMPLOYEES \
--from-beginning \
--max-messages 1"You’ll see a similar output:

You should see JSON containing:
- before
- after
- op (operation type)
- ts_ms (timestamp)
This confirms Debezium is producing proper change events.
Check Replication Lag
Consumer lag indicates how far behind the sink connector is.
docker exec kafka kafka-consumer-groups \
--bootstrap-server kafka:29092 \
--describe --all-groupsThis is the output:

Important Columns:
- CURRENT-OFFSET
- LOG-END-OFFSET
- LAG
What Should Be Validated Before Cutover?
Before switching applications to PostgreSQL, validate and ensure the following:
INSERTreplicationUPDATEreplicationDELETEreplication- Schema evolution handling
- Large transaction handling
- Connector restart recovery
- Zero consumer lag
- No connector task failures
Only after successful validation should you proceed with final application cutover.
Final thoughts
Testing and validation are the backbone of a successful zero-downtime migration. With proper monitoring, topic inspection, connector health checks, and DML validation, you can confidently ensure that your CDC pipeline is production-ready.
In this two-part series, we have:
- Built a fully open-source CDC architecture
- Enabled Oracle LogMiner-based change capture
- Streamed real-time changes through Kafka
- Applied them into PostgreSQL
- Validated end-to-end synchronization
With this foundation, your Oracle to PostgreSQL migration can move forward with confidence, minimal risk, and near-zero downtime.
Here is the previous blog post on how to build a CDC pipeline.
https://opensource-db.com/oracle-to-postgresql-migration-cdc-with-debezium-apache-kafka/