Introduction
In today’s world of databases, performance is one of the key aspects that need to be taken care-of irrespective of the size of the database. If you’re in charge of managing a PostgreSQL database, ensuring peak performance is undoubtedly a top priority. Enter pgbench, PostgreSQL’s own benchmarking powerhouse, designed to help you simulate workloads and test different database strategies to optimize efficiency. Whether you’re a seasoned DBA or just starting out, understanding how to leverage pgbench can be a game-changer for your database operations. This comprehensive guide will cover everything you need to know to get started with pgbench, interpret its results, and implement its insights for optimal database performance.
pgbench
pgbench is a benchmarking tool included with PostgreSQL that simulates a standard workload. A simple program for running benchmark tests on PostgreSQL.. By default, pgbench tests are based on the TPC-B benchmark, which includes executing 5 SELECT, INSERT, and UPDATE commands per transaction. It is available as a part of the PostgreSQL installation. Using pgbench , we can simulate various workloads on PostgreSQL databases by generating multiple client connections and also by predefined scripts or set of parameters.

Setting up and running my first pgbench test
pgbench should be invoked with the -i (initialize) option to create and populate these tables. While initializing pgbench -i database_name, it creates four tables pgbench_accounts, pgbench_branches, pgbench_history, pgbench_tellers dropping any existing tables of these names.
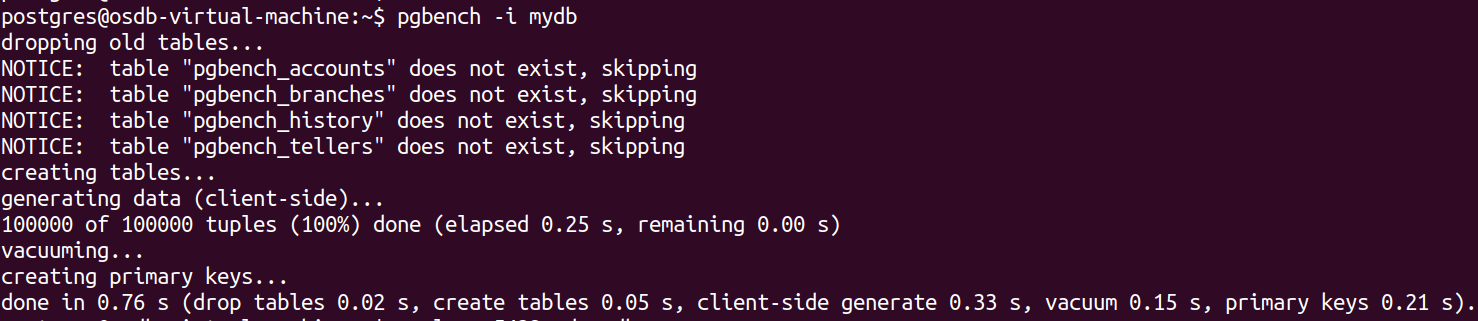
However it will check for the previous tables of these names and create again whenever -i (initialize) is given. In order a scale up , with a scale factor -s of 20, it will insert data into the tables to represent a workload 20 times larger than the default scale. Each tuple inserted represents a row of data in the database tables as shown below.

There are various parameters in pgbench to perform benchmark tests. The most common options are -c for number of clients,-j for number of threads, -t for number of transactions, -T for time limit and -f for specify a custom script file.
Running pgbench
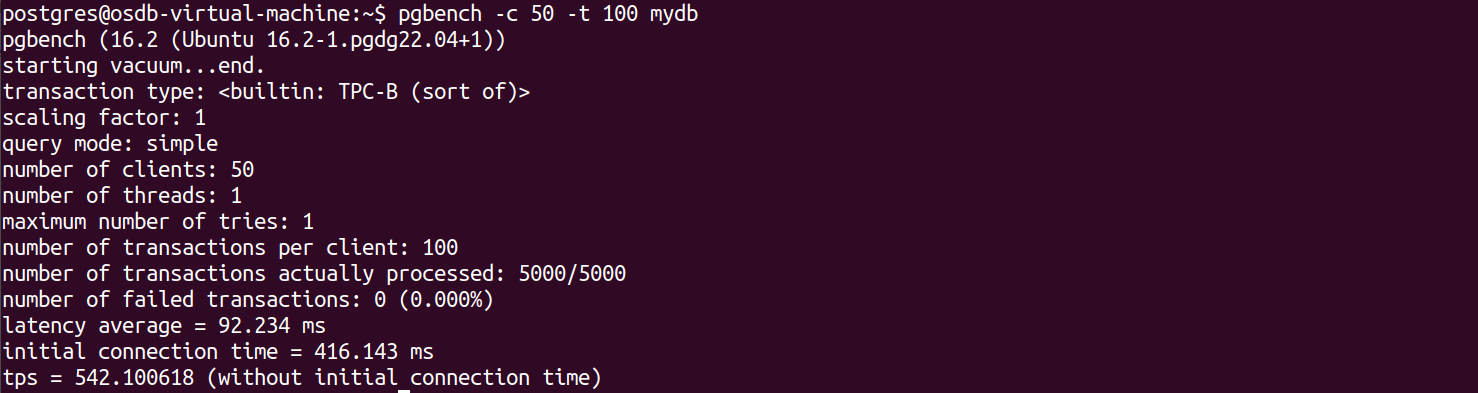
Simulating the workload with 50 client connections and 100 transactions per client to database mydb
Understanding the Output
Let’s analyze the output, there are some defaults that will be considered such as scaling factor =1 , number of threads =1 if you didn’t give them in input.
Number of clients , Number of transactions per client is given as input to pgbench and number of transactions actually processed is the product of those two. There are zero transactions failed.
Latency average is the time taken to respond for a given request. It is measured in milliseconds . here it is 92.234ms
Initial connection time is the time taken for the client to establish connection with the server. Here it took 416.143ms
Most important is tps i.e transaction per seconds , it refers to the number of transactions processed by the system in one second time interval. It varies based on the complexity of transactions(or query) , system resources, concurrency levels, and database configuration. It is better to have high tps.
Tips and Tricks
- Understand the workloads – It is important to understand the workloads on application and simulate accordingly using customized SQL scripts and adjusting scale factor.
- Controlling concurrency level – We can control the concurrency level in the
pgbenchtest using the options -c and -j accordingly. - Monitor System Metrics – Use system monitoring tools such as top to monitor CPU usage, memory utilization, disk I/O, and network activity during
pgbenchtests. - Tune PostgreSQL configurations – Adjust
postgresql.confparameters , such asshared_buffers,max_connections,work_membased on results. - Run multiple tests – To get the accurate assessment on performance , run the multiple
pgbenchtests. - Documentation – Documenting the methodologies & results of your testing activities will help in further analysis.
Common pitfalls to avoid in database benchmarking
- Doing the benchmark testing without understanding the workload.
- Running the test on the insufficient CPU, memory, storage, and network resources to support the expected workload.
- Incorrect benchmarking tools and methodologies can lead to incorrect results.
- Not testing on realistic conditions or failing to replicate the environment conditions leads to improper results.
- Considering the result of single test rather than the average of multiple tests
- No proper documentation
Summary
To summarize, effective benchmarking is crucial for the optimal performance and scalability of databases.By leveraging benchmarking tools such as pgbench, database administrators and developers can simulate real-world workloads, measure performance metrics, and identify areas for optimization. However, successful benchmarking requires careful planning, execution, and analysis.In this blog, we have explored some features and results of pgbench including tips , tricks and also common pitfalls need to be avoided in database benchmarking.
Thank you and stay tuned for more…