Production PostgreSQL deployments demand high availability. Applications requiring four or five nines of uptime need resilient database clusters built on carefully designed architectures.
High availability isn’t achieved through a single solution—it’s an ecosystem of specialized tools working together. Each component serves a specific purpose in maintaining continuous operation.
Designing HA architecture begins with understanding client requirements. Every application has unique needs, and the architecture must reflect these differences. The design process involves balancing several competing concerns:
- Complexity: Each additional tool increases system intricacy.
- Security: More components mean more attack surfaces to protect.
- Resources: Hardware, network, and storage requirements multiply.
- Expertise: Teams need knowledge across multiple technologies.
- Cost: Initial investment versus long-term operational savings.
Despite best efforts in designing redundant database clusters, one question often gets overlooked: Have we truly eliminated every single point of failure(SPoF) along the entire connection path, from the database server all the way to the client application?
Most teams focus on database-level redundancy—replication, failover mechanisms, and backup strategies. Yet failures can occur anywhere: load balancers, network switches, connection poolers, DNS servers, or even client-side connection handling. A comprehensive HA strategy must trace the entire data path and address vulnerabilities at every layer.
True high availability means examining not just your database tier, but the complete journey of every query from application to storage and back again.
Potential tools of Postgres HA
Let’s have a high level overview on high availability tools:
- Cluster Management and Failover
- Patroni: Automated cluster management using distributed configuration stores (etcd, Consul, ZooKeeper) with built-in failover and health monitoring.
- repmgr: Lightweight replication and failover manager that simplifies standby setup without requiring external dependencies.
- pg_autofailover: Automated failover solution using a monitor node, ideal for smaller deployments.
- Connection Pooling and Load Distribution
- PgBouncer: Lightweight connection pooler that reduces overhead by reusing database connections for improved performance.
- Pgpool-II: Feature-rich middleware providing connection pooling, load balancing, and automatic failover.
- Load Balancing
- HAProxy: Robust TCP/HTTP load balancer that distributes traffic and performs health checks across PostgreSQL nodes.
These tools serve different purposes in the HA stack, but their real power emerges when they’re integrated together. These are some of our blogs on High availability:
- PostgreSQL HA with Patroni
- Configuration of Patroni
- Integration of PgBouncer and HAProxy with Patroni
- High availability setup with repmgr
There’s no universal “best” architecture. The key is to try different combinations of tools and select the ones that align well with your specific requirements without over-engineering.
Eliminating SPoF
In typical PostgreSQL HA setups, you might deploy:
HAProxyfor load balancing traffic across database nodesPgBouncerfor connection poolingPatroni,repmgr, orpg_autofailoverfor database failover
But here’s the catch: If you run a single instance of HAProxy or PgBouncer, you’ve simply moved your single point of failure from the database to the proxy layer because of cluster management tools. When that single HAProxy or PgBouncer instance crashes, all client connections fail—even though your PostgreSQL cluster is perfectly healthy and has already failed over to a standby.Can deploying multiple HAProxy or PgBouncer instances alone eliminate the single point of failure at the proxy layer? An additional mechanism is required to automate client connection failover in case a proxy node fails.
What is Keepalived?
Keepalived is a Linux service that implements the VRRP (Virtual Router Redundancy Protocol) to provide high availability for network services. In the context of PostgreSQL HA, keepalived manages a floating Virtual IP address that automatically moves between servers based on their health status.
Key Features:
- Manages Virtual IP addresses that float between servers
- Performs health checks on services
- Automatic failover when primary instance fails
- Split-brain prevention through VRRP priority system
- Lightweight and battle-tested in production environments
How Keepalived Eliminates SPoFs
Instead of pointing clients to a specific server’s IP address, they connect to a Virtual IP (VIP) managed by keepalived. When the active HAProxy or PgBouncer server fails, keepalived detects the failure and immediately assigns the VIP to the standby server. Client applications continue connecting to the same VIP without any configuration changes.
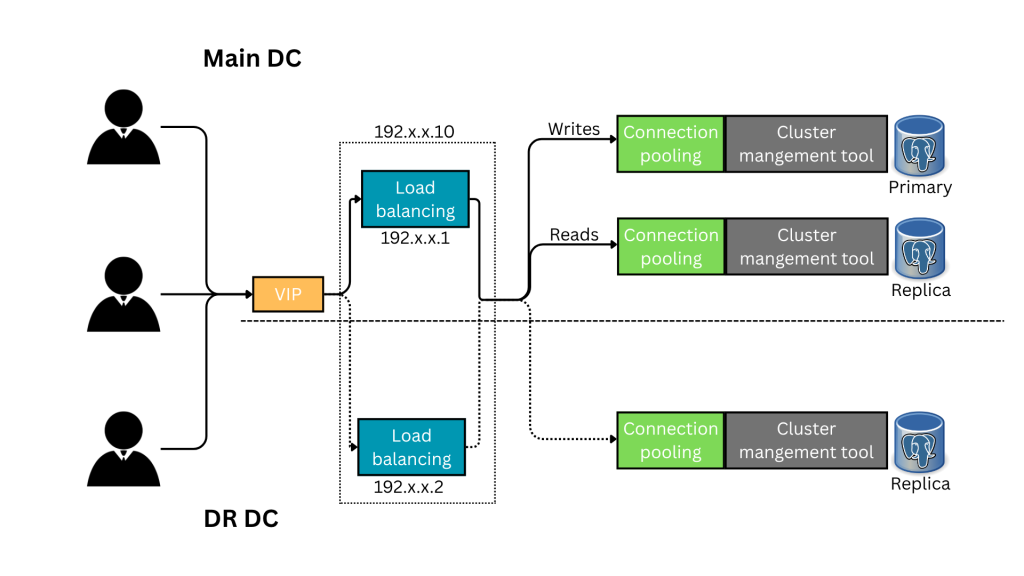
Understanding the connection flow:
- Client Application will be connected to the VIP(
192.x.x.10) to remain seamless in case of failure. - Keepalived manages VIP address that float between servers based on their health status.
- Load balancer will redirects
writesto the primary of the cluster andreadsto the standby via connection pooler based on how you configured the load balancing.
Note: You can choose the order of load balancing and connection pooling components in your architecture and assign the VIP accordingly. If your setup doesn’t require load balancing or connection pooling, the VIP can instead be assigned to your cluster management layer.
Keepalived configuration
Keepalived requires a health check script to monitor the status of the server at the layer where you want the VIP to float. This layer can be any component with two or more servers — such as HAProxy, PgBouncer, or even the database layer itself.
The Health check script should determine the service health. If the keepalived is configured on top of database layer, you can create a script with double confirmation by exacting which node is primary from cluster status (depends on which cluster management tool you prefer) and the output of the pg_is_in_recovery .
On Node1 (Master)
# Keepalived global settings
global_defs {
router_id LVS_DEVEL
# Optional: notification settings, etc.
}
vrrp_skip_check_adv_addr
vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
vrrp_script chk_pg {
script "/path_to_script.sh"
interval 2
weight -50
}
vrrp_instance VI_1 {
state MASTER
interface <your_network_inferface>
virtual_router_id 51
priority 100
advert_int 2
authentication {
auth_type PASS
auth_pass <Password>
}
virtual_ipaddress {
<VIP_address>
}
unicast_src_ip <current_node_IP>
unicast_peer {
<Remaining_node_IP>
}
track_script {
chk_pg
}
}On Node2 (Backup)
In Backup node , there will be only two changes.
state BACKUP
priority 51Verify
You can simply verify but checking hostname
hostname -IYou can see the server IP address along with VIP address on Master node. Once you configured keepalived , we can test it by stopping the services on node1 and check whether the VIP is shifting to the node2 which means now your application can connects to VIP regardless of node failures.
The combination of Keepalived with HAProxy and Patroni forms a holistic high availability architecture, enabling:
- Elimination of single points of failure across database and proxy layers.
- Transparent failover with client connections seamlessly migrating to healthy nodes via the VIP.
- Automated health checks and failover triggering through custom scripts, enabling precise control of failover behavior.
- Simplified client configuration with a stable VIP endpoint regardless of underlying failovers or maintenance.
- Scalable and resilient architectures suitable for demanding environments requiring four or five nines of uptime.
Conclusion
Achieving true high availability in production PostgreSQL deployments demands a carefully designed ecosystem of specialized tools addressing every layer of the connection path—from client applications to database storage. While clustering tools like Patroni, repmgr, or pg_autofailover handle failover and replication at the database level, higher layers such as connection pooling and load balancing must also be made resilient.
Tools like HAProxy provide robust load balancing but can themselves become a single point of failure if deployed as standalone instances. Keepalived secures this weak link by managing a floating virtual IP (VIP) address shared among multiple HAProxy or PgBouncer nodes, ensuring automatic failover and continuous client connectivity even if individual proxy nodes fail.
This multi-layer fault tolerance, combined with careful balancing of complexity, security, resource allocation, and expertise, provides the foundation for truly resilient PostgreSQL deployments that maintain continuous service and data integrity under failure conditions.
By addressing all potential failure points—from the database cluster to the proxy layer and VIP management—Keepalived ensures a production-ready architecture that meets stringent uptime SLAs and simplifies operational management of highly available PostgreSQL infrastructure.